Finer04's Blog
首页
乱写一通
脑洞破文
随便谈谈
当前播放.page
硬盘不行就不要依赖 swap 了
Finer04
November 23, 2019
1761 字
文章目录
最近应领导要求,给我司的某些设备都上了 Zabbix 监控,意思就是以后再出问题都不能赖厂商了,有事都把锅丢给我,爷佛了,被前同事不断套路下去,接了这个粪坑。弄了之后观察了一个月,某台信息设备的工作效率确实负载一高后,任务的执行效率就会失效,只有等到负载低了工作才正常,怎么办如果拖住又出问题了又tm甩锅给我背,那肯定没办法啊。 问了厂商的主要对接人,他说某个应用怎么只跑了一个核,没办法将 CPU 的负载压下去啊。这样的话爷tm岂不是要凉了?先试了下重启大法看看有没有问题,重启后,过了十几分钟负载还是突然上去了,看了 `top` 都跑了 23.00 了,线程都快跑完了,不可能呀这可是 E5-2420v4 呀,这机房的是设备业务量都不是很大,怎么还能跑满吗,厂商说换设备或重装试试咯。 不行啊,换设备和重装这空白期又出什么岔子到时又赖我,横着竖着也是死,爷觉得肯定是还有其他因素导致的,或者服务器哪个地方到了瓶颈,那就先挂着 `top` 观察下咯 ## 现象 (注:业务进程已打码) ### 是不是 CPU 不行? 在负载变高的时候,CPU 的使用率会上升,主要是业务进程的占用率变高,但这也看不出什么,需要看看这 CPU 占用率变高是哪一方面影响的,我们先使用 `top` ,在点击数字键 1 ,看 CPU 每个逻辑处理器的情况 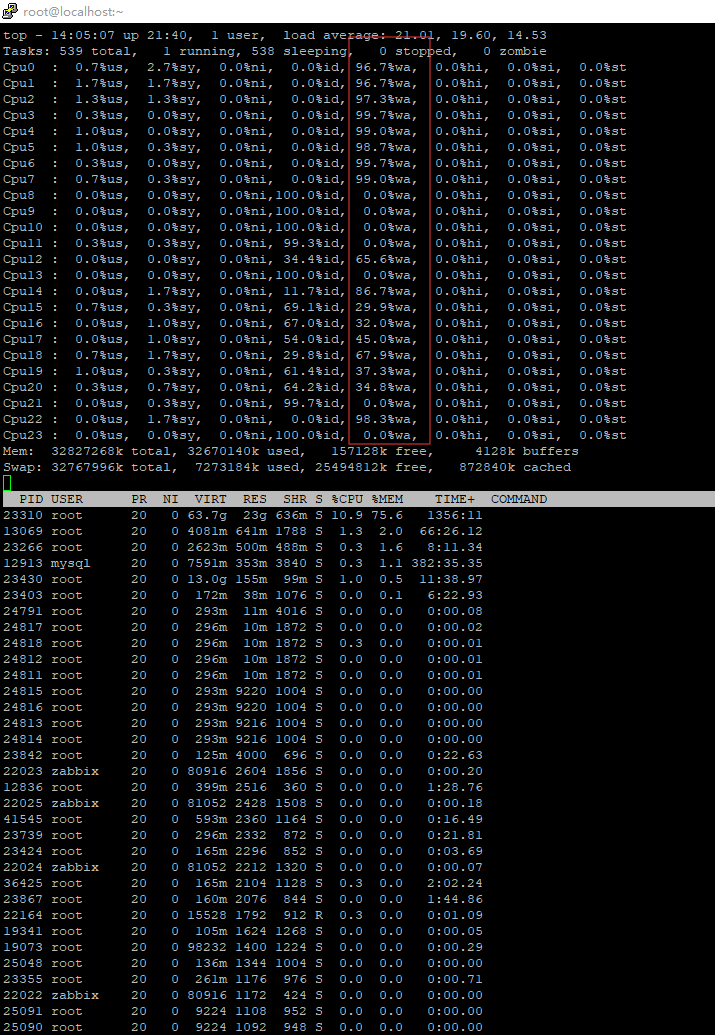 再看看 Zabbix 的该时间段的情况 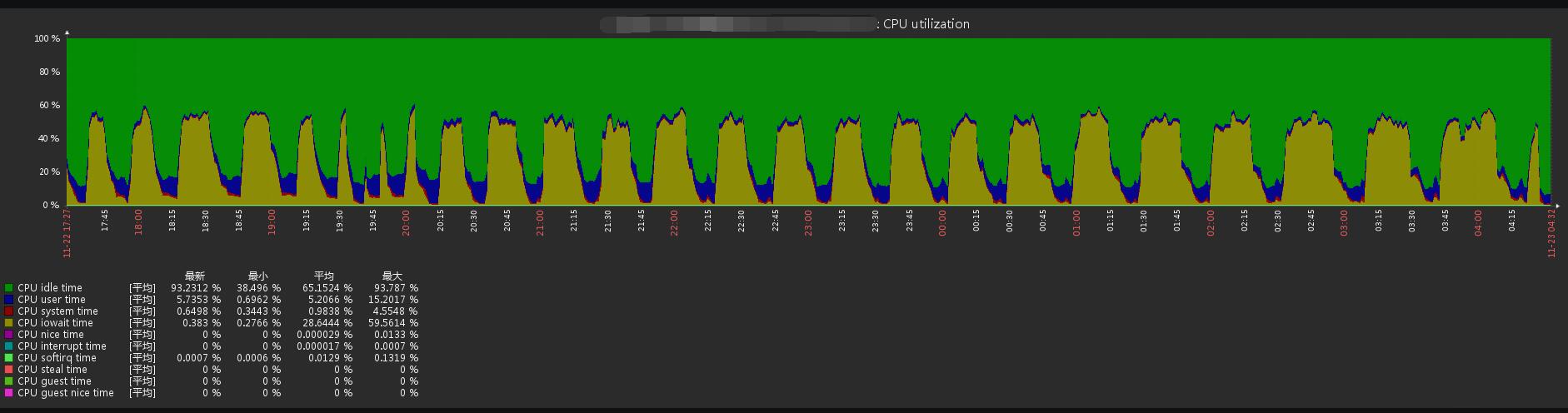 看了下,user time 的占用很低,但最高的是 wa 这个,都到了 96% 了,这就说明 CPU 等待 I/O 读写卡在队列中,是内存不够用?还是硬盘的写入太慢?那就继续看看那个进程占用那么多 I/O 资源吧。 ### 是谁在用存储资源? 同样在负载最高的时候,使用 `iotop` ,再对照 `top` 的画面,除去业务进程的正常读写,突然就多出了 kswapd 这个进程,简单来说这个进程是在内存不够用的时候,将部分内存上的数据交换到swap空间上,以便让系统不会因内存不够用而导致挂掉或者更致命的情况出现。 再看看 iotop,业务进程和 kswapd 的 I/O 的比例都是 99%。 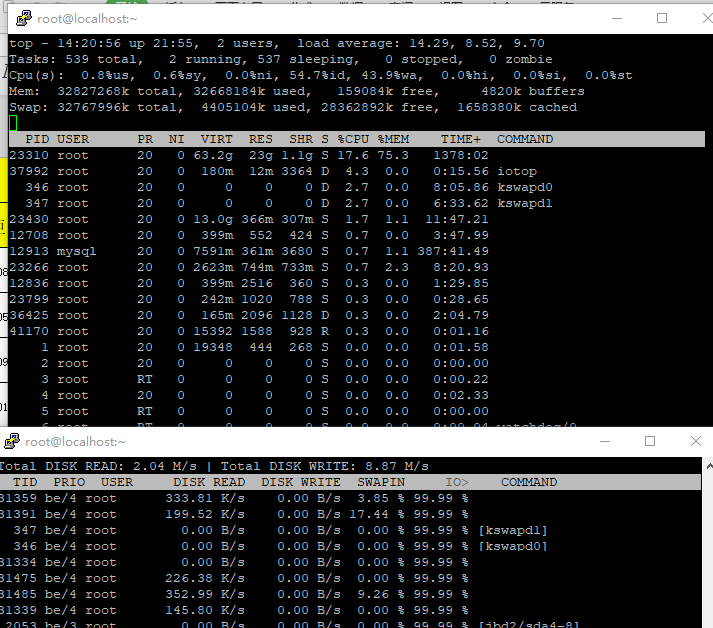 嗯?为什么会用到 swap ?是系统的内存不够用吗,这可是 32G 内存的哦居然还不够用。但的确,看物理内存的空闲内存已经只剩 135M 了,去看了眼 `free -m`,swap 的分区占用突然升高了,物理空闲内存所剩无几了。但服务器的硬盘很菜,交换分区写得又慢,才导致 io 都一直站在等待 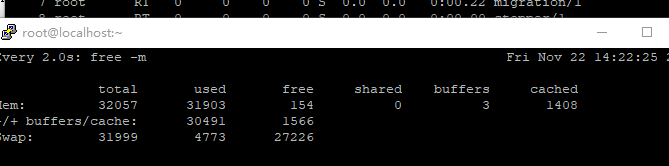 再看了眼内存的趋势图,当负载高的时候,内存与 CPU 的占用表现是一致,那我懂了,肯定是内存到了瓶颈导致负载高了不少。  ## 解决 那么,有什么解决的办法呢?那肯定只能——加内存啊。看上面的内存图,在最右边的就是已经加好内存的,都没有再跌过了,而且负载也正常了不少,只有 0.99 左右。 swap 交换分区需要依托硬盘划分一个分区用来交换内存,但如果硬盘性能过低的话,不但影响自身业务,还会跟业务抢占资源,没有固态硬盘的话,放在机械硬盘真的等着卡死。加内存就对了
Linux
Swap
I/O
评论已关闭
▲ Top
评论已关闭