Finer04's Blog
首页
乱写一通
脑洞破文
随便谈谈
当前播放.page
MTR-Center 建设笔记(弃坑)
Finer04
July 26, 2021
3458 字
文章目录
这玩意还没做完,还在做前端,不过近期又要轮班了可能没有多少精力做了高强度摸鱼,高强度玩恋活工作室,不过还是谢谢笔记吧,上一个开发笔记还是链路监控平台呢。 众所周知,网络质量监测都是以丢包率和延时为主要指标,这两个指标一有异常就绝对不行了,客户会感知到明显的卡顿。目前我公司依旧还用着 Zabbix 作为网络质量监测的重要平台,当然要知道一点的是,发现异常就得做个测试信息提供给运营商,一般得上检测设备对目标IP 进行 MTR 才能获得一份诊断报告,然后交给运营商报障才行。但我们目前这一步基本以人工为主,曾经我们确实是用过 Zabbix 的动作自动获取,但都有一个问题:突发异常无法第一时间获取到,或队列阻塞了,导致最后获取结果已经是恢复正常了。可某些时候有些傻 X 客户很钻牛角尖,一丁点的抖动都要报障过来,客户经理就会找老板,老板就会找我们领导,我们领导就会找我们怎么没报障呀?! >“没抓到啊,这丢包就丢了10秒就没了!怎么报运营商啊!” >“人家客户都报过来了,你是不是找借口啊” > “干,你自己看聚合图形,人工哪有这么快啊!” > “之前 Zabbix 不是有动作吗,一丢包就会自己获取结果” > “都关了一百年咯,以前那套还用着 SSH 远程发送指令呢时间开销大啊。现在虽然升级了,但我们用 Docker 的镜像快搭的呀,里面没有 mtr 工具啊!要不今晚挂个一小时 mtr 咯!” > “这样下去不是办法啊,赶紧整一个啊” 这是上个月领导与我的聊天(内容未必是这样),那就搞咯搞咯,首先我得分析下以前的自动动作的问题点。 ## 以前的自动获取数据的方式 以前的大佬当初搭建 Zabbix 是 3.0,3.0 当时的动作没有办法服务端直接下发命令到 Proxy(可以直接下发到 Agent),为什么必须要下发到 Proxy 呢?因为 Zabbix 的网络监测功能是利用简单检查功能实现的,就是直接使用服务器本机测 Agent 的 IP 的网络情况,但这个 Agent 的话,对于我们测全国各地的 IP 的话,明显是没办法弄的,直接交给 Proxy 去下发指令才行。就可惜只有 4.0 或以上的版本才能直接下发到 Proxy。 以前同事设计的 3.0 使用的自动动作是,中心端用 SSH 免密的方式向节点端建立连接,然后下发 mtr 命令到服务器再执行,最后将 mtr 的结果用邮件发送到邮箱中。这意味着如果以后有新的节点端,我除了搭建基础服务外,还要搞 SSH 免密、配置系统邮箱,烦死了!而且还要知道一点的是,SSH 建立连接可能会存在一定的时间开销,所以实时性没那么高。 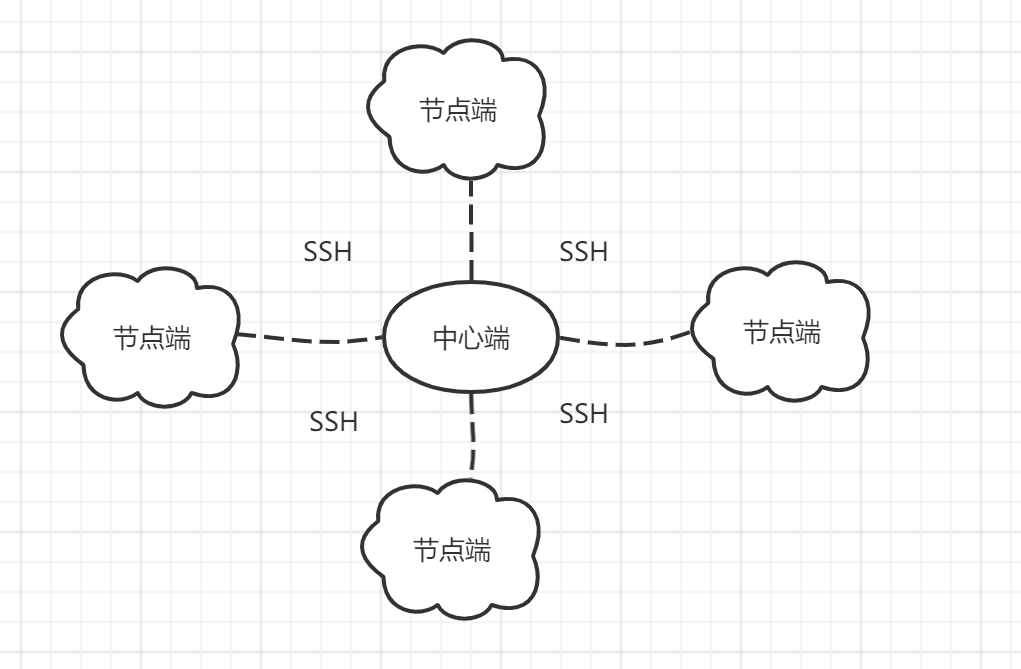 但现在呢,虽然我在去年升级 5.0,理论和实际上都能支持下发到 Proxy,但是呀,看过我之前的 Zabbix 升级迁移的文章的大佬都知道,我是为了保持双版本运作,节点端有旧版 3.0 的二进制服务和 5.0 的容器服务一起共存,尽管我已经把旧版全关了,但我也没心情每个节点都老实搭个二进制服务呀,容器他不香吗?但是容器他又不是所有工具都有,就算能下发命令到 Proxy,但容器里面没有 mtr 这个工具啊,我也不可能一台一台进去 `exec` 再部署吧,这个就不符合容器的价值了。Ansible 的剧本不会的我只能找找其他办法。 反正有以下痛点,使我不得不关闭旧版的自动获取功能 - 有时间开销,存在不及时的问题,人工上去都比自动获取快。 - 部署起来麻烦,后期维护成本很高。 - 邮件太多了,反而还不好找! - 不适合现代的潮流。 ## 现在的构思 既然不想在代理端的容器搞服务,那想想一般 Linux 系统会有什么工具呢?那就是 curl 了啦!也就是说,我可以自己做一套 API 服务,让节点代理端的容器直接发送请求到节点端的数据收集服务,数据收集服务就自己抓数据并存下来就好了。好,很有精神,那就做起来吧! 设计刚开始,我考虑了这些问题: - 用什么方式做服务? - 用 Python 的 Flask 做一个 Web 服务端(不会 Django,而且对于接口来说太庞大了) - 要不要弄队列?来多少测多少不会有问题吧? - 还是弄个队列好一点,不过我还没试过一口气来 500 个请求服务器能不能撑得住 - 怎么展示? - 数据结果会归档到指定目录,以日期作为索引,到时候写个接口直接查询结果就行了。再弄个前端把全部节点整合好。 然后关于队列的话,这个问题我一直纠结是来多少测多少,还是得排队测呢?如果考虑到实时性的话,应该来多少测多少。但要考虑到一个场景,互联网是不稳定的载体,我们无法保证所有被检测的公网 IP 都能稳定不丢包,有时候丢一下的话也会触发动作。假设我们用队列的模式,服务器还在测之前的请求,其实也可能会存在滞后性。但来多少测多少,我主要还是担心会卡死。最后还是选择队列的形式,并行多个任务的队列。 如何部署服务,我也趁这个机会学习使用容器的来打包应用和使用,这样到时候我只要一键部署就可以了,省去了很多部署的环节。 队列我选择 Redis (主要是简单)帮我自己推送到 Worker,但是工人只能单个进程做单个任务,因此我需要多开几个进程同时做多个任务。按照以下的流程,Zabbix 只要向代理端下发命令 `curl http://127.0.0.1:8081/api/mtr?ip=x.x.x.x` 就行了。 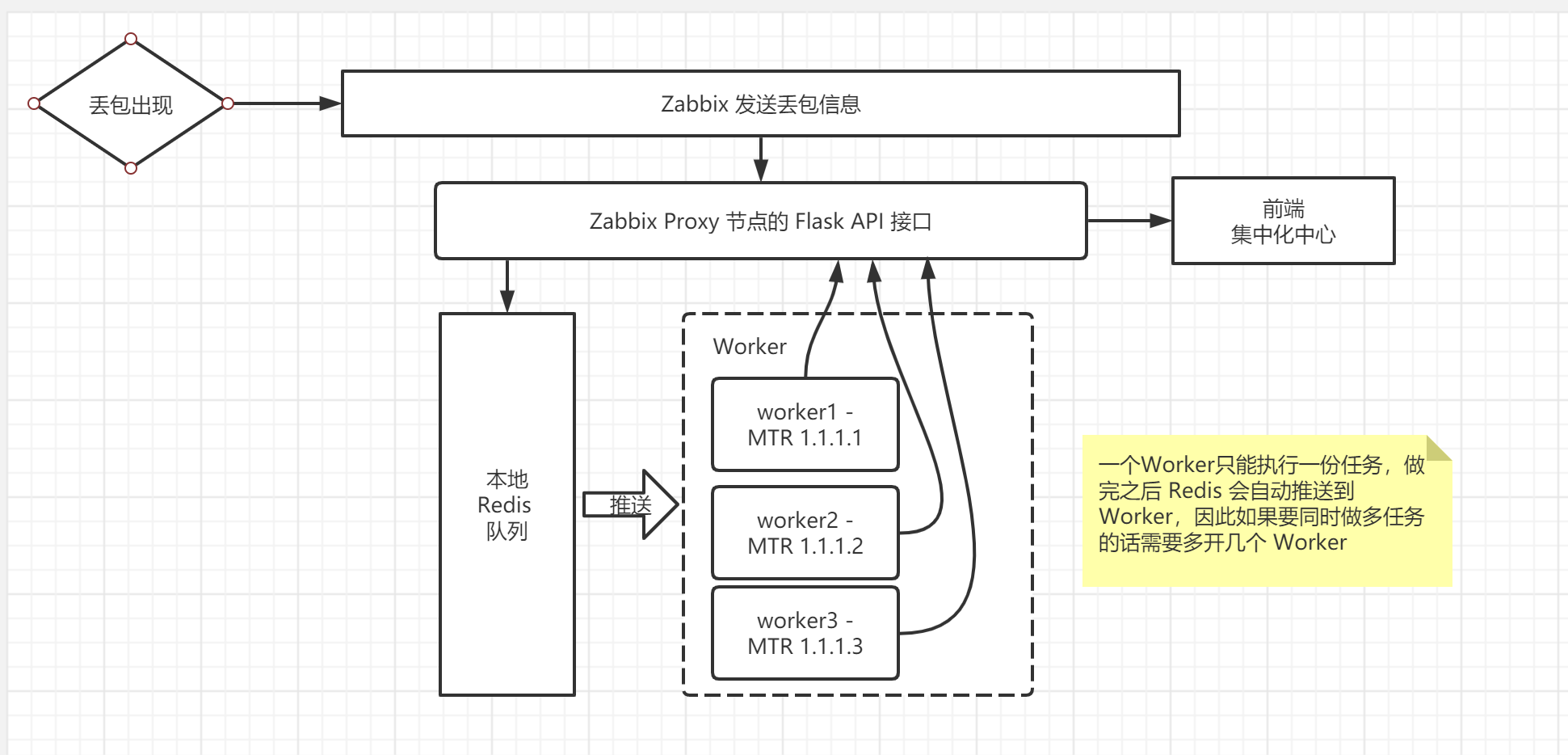 ### 其实,还是有痛点的。 在网络异常在比较极端的情况下,不要说 http 请求了,连 ping 都可能不可达,到时候下发了指令到服务器还不是得等响应,等响应到都已经恢复正常,收集了个寂寞,如果解决不了这个痛点的话,这个 API 只不过是个换皮的 SSH 下发方式而已。因此我想了两个解决方案,但实现起来在程序上没什么思路。 #### 使用内网 IP 这个是好办法,但这就意味着每个节点都得弄个内网 IP,走流程比较麻烦,只能说重要节点搞一下而已。 #### 内部应急探测 我们不能只依靠 Zabbix 知道丢包了才做行动,有时候出口中断了,代理端是无法把数据返回到中心端,中心端还以为节点网络没异常呢。如果担心结果不实时的话还不如让节点自己测其他节点的 IP,有异常直接自己在本机做 MTR,不用等到 Zabbix 通知到才去做,等到故障恢复了我们也有机会上去看。 但是这个我得看看在语法上怎么判断是否存在丢包,怎么获取现有的节点的 IP 列表。这个方法是我想到的最优解了。 ## 开发过程的疑问 ### 怎么多开工人? 上面也说了,Worker 只能单进程做单个任务,任务结束后会自己做下一份任务,如果真的发生多个丢包的话一个一个来有什么意义呢?在网上教程说可以多开几个工人进程就能同时做多个任务,那我应该怎么弄?百度了一下,可以使用 supervisor 做服务管理和多开进程! 我们创建一个 worker 的 supervisor 的配置文件,多余的参数可以抄作业,但 `process_name` 和 `numproces` 要加上去,首先 `process_name` 是为了让进程名称不冲突(我是这样理解的,因为我不加的话跑不起来),`numproces` 是开多少个进程,我写六个是测试用而已,理论上开个 50 应该不是问题(还没试,得看服务器线程决定) ``` [program:worker] command=python3 /home/mtr-report-flask/worker.py process_name=%(program_name)s_%(process_num)02d numprocs=6 ``` ## 待补全 等我开发差不多再写点内容吧(上一篇说待补全都弃坑了)
评论已关闭
▲ Top
评论已关闭