Finer04's Blog
首页
乱写一通
脑洞破文
随便谈谈
当前播放.page
回忆憨批过去与爬虫解析黑历史官方备份并存到数据库
Finer04
January 10, 2021
7050 字
文章目录
很喜欢以前说过的一句话:“天下没有不散的宴席,也没有永恒存在的事物”。也很喜欢罗太君说过的一句话(并没有),图转微博:  确实,陪伴了我整个初中高中和半个大学的腾讯微博终于在平台竞争中落下帷幕了,在 2020 年 12 月 30 日终于停止运营了。爷的黑历史终于消失在互联网的数据库中了,妈的现在看回以前的言论实在是过于脑瘫,不得不怀疑当年的我是不是现在的我。但也不得不否认,那期间也是我认识的、有深交的网友最多的时候。而现在,基本退居到 QQ 群聊天(在自己以前的早就转型的游戏公会群和其他闲聊群),在夹去阴间微博基本上只看微博只点赞,不怎么发表微博和评论,所以基本上关注的,看的都是以前的认识的网友或营销号、数码博主等什么的微博。 不管怎么样,现在也的确没多少心思花在网络上,有些时候我说话不是很好,越聊越尬。所以现在的视角看回以前的问题发言,确实像个铁憨批一样,我就挑几条傻逼微博说说吧,当然我只会挑自己的傻逼发言。当然回忆就是自己回忆而已,没人在乎您自己以前活得怎么样。 ## 憨批发言 不太想截图,而且本文后面是说如何爬虫解析,所以微博内容都用 json 来写。 ### 第一条微博 "61186": { "author_name": " Finer04 ", "weibo_date": "2010-07-20 18:19:44", "post_content": "Galgame很好玩.", "image-container": [] } 2010 年就开始摸黄油了,实属牛皮,我记得当时见到 Hscene 都要遮住屏幕跳过;现在玩黄油看到这些画面都无动于衷,感觉没意思也是照样跳过。还记得第一次摸的 Gal 还是秋之回忆 2,好像还是用 PSP 玩的吧,我也忘了当初我是怎么玩下去的。我只记得第一次是 BE,再二周目就 GE 了,当然我也忘了究竟剧情是不是一本道只有单线,反正那时候是没有看攻略玩的。 第二次玩,也算是我正式入坑 Gal 的作品,当然原作也是我的入宅作之一。作为 2010 年最现象级的动画,那就只有《俺妹》了。确实那时候是我第一部全通剧情的作品,在原作动画和小说都无法满足我的欲望,刚好就出了《俺妹》的官方 ADV 游戏。记得似乎后面也出了类 FD 的续作 ADV 吧,都玩过了。但是嘛,现在剧情都忘光了。 ### 二刺猿傻卵竟是我自己! "61155": { "author_name": " Finer04 ", "weibo_date": "2010-07-27 18:06:59", "post_content": "最近看无限卖萌的MAD(PS.萌:可爱的东西).吾人的荷尔蒙爆发了..", "image-container": [] } 正所谓,入宅有几个阶段:`路人 → 二刺猿傻卵 → 小鬼 → 我不是二刺猿`。当年自己还是在第二层,现在看到这些呐呐呐发言都觉得只有铁nt才会在网络倒彩虹傻屁。 算了不看了,6W条微博都是水,而且还是版聊多。 ## 正题 由于官网发过来的是 HTML 的备份数据,高达 30M(毕竟水太多了),光是我这轻薄本加载所有内容都比较卡,而且用办公网看也不是很好(所有图片都会自己下)。而且这种数据我希望存在自己的数据库,自己再弄个系统展示出来。也看到了养老群的大佬也写了解析脚本来处理自己的数据。就当练手吧,自己也写了个爬虫,反正我 Python 实在是太瓜皮了。 主程序代码:https://github.com/finer04/wb-bk 对,我没写注释,所以下面会介绍模块。也很容易理解 ## HTML 结构 官方的 HTML 结构也很简单,我稍微看了下 HTML 结构,是这样的 **原创微博** - div.item - div.author - div.date - div.post - div.image-container - img.single-image - ul.link-wrap **转发微博** 形式就是 原创微博+转发微博类(原创微博的结构) - div.item - div.author-name - div.date - div.post - div.image-container - img.single-image - div.repost-content - div.author - div.date - div.post - div.image-container - img.single-image - ul.link-wrap 对,就是这么简单粗暴,我还以为转发微博会有一个类能wrap结构,结果没有,就是一条一条来的。 ## 需求分解 于是这就比较好用 BeautifulSoup 来解析了。我先分了三个模块来实现需求 1. 读取 HTML 所有内容 2. 爬取所有 img 格式的图片地址并多线程下载 3. 分析微博的信息 4. 导出 json(先做了主体功能先,我当初嫌麻烦是直接把 json bulk 到 elasticsearch 数据库的) 下面的代码都是直接复制一小段的,建议看原版代码 ### 读取数据 我是用二进制的形式读取数据,如果不用二进制读取的话,光是这一步就要消耗大量资源去读取,非常慢。如果使用二进制读取的,基本秒读完,最后再转换成 UTF-8 就行了。 def readhtml(): rawhtml = '' with open(config.filename, 'rb') as f: fraw = f.read() f.close() rawhtml = fraw.decode('UTF-8') return rawhtml ### 爬取所有图片 这个就简单了,我用了最懒的方法,直接匹配整个 html 代码,利用正则表达式将所有 URL 匹配出来并加到列表中。 微博的URL地址是 `http://t1.qpic.cn/mblogpic/26283d214ae9cbdd31b0/2000`,其中 `t1` 的 `1` 都是不同的存储节点,后面的 `26283d214ae9cbdd31b0` 可能就是 md5 了,但这个没什么意义,只要在分隔符 '/' 前匹配所有字符串到就行了,最后 `2000` 就是原图尺寸大小,保险起见也用正则代替。 def find_html_img(self): img_list = [] regex = re.compile(r'http://t[0-9].qpic.cn/mblogpic/[A-Fa-f0-9]*/[0-9]*') tmp = re.findall(regex,rawhtml) img_list = img_list + tmp return list(set(img_list)) 下载就简单,直接用 requests 下载,以二进制的写入到文件夹。但是文件名的话,我用分词方法,将 md5 和 图片尺寸作为文件名,保存为 `md5.2000.jpg` 这样。多线程方面我是直接用封装好的 threadpool,毕竟原生的多线程真的不会用。 def downloadall(self,url): global now_num filename = '.'.join(url.split('/')[4:6]) + '.jpg' now_num+=1 print(f'({now_num}/{allpiclen}) 正在下 {url} ') try: reponse = requests.get(url,timeout=10) with open('img' + '/' + filename, 'wb') as f: f.write(reponse.content) complate_url = url except requests.exceptions.RequestException as e: print(f'{url} 下载失败') failed_url = url 执行过程: > 动了,动了,黑历史挖掘机它启动了。 —— S_Finer04 > 2020-10-1 16:23 来自 weibo.com  ### 分析微博信息 我用字典存单条微博数据,然后再按照每条微博的序号做个字典,将单条微博数据作为 value 存进序号 key 中。用 bs 解析的时候,找出所有 item 的 div,用枚举的方式一条一条解析。顺便一说,用 bs4 解析我选了 `html5lib`,原生的 htmlparser 速度非常慢。换了 html5lib 就很快啊。方法(def)的话我直接套在循环中,因为 class 下面都是直接执行的代码,我也不知那时候我是怎么想的。 由于看上面的结构,div 的结构都很直接来。对转发的微博来说,有在原创微博中多了个 `repost-content`,就要判断 `.item` 有没有这个 `repost-content` 这个转发类,有的话又要重新执行获取文本和图片地址的方法。为了对这两种微博,因此在 `getdivtext` 做了两个模式。这也是为什么后面的主体执行代码有 1 和 2。 因为爬取图片这个方法是已经提前做了,因此对原创微博的图片 URL ,我以 '\' 分割字符串的方式,存入字典的 URL 地址只需跟爬取好的图片文件名格式一样就行了。 因此整段代码是这样的,我很少用 class ,所以可能写得不是很正确。 class wbhtml(object): def __init__(self,rawhtml): self.rawhtml = rawhtml def analyzeitem(self): itemdict = {} soup = BeautifulSoup(rawhtml,'html5lib') item = soup.find_all(name='div',attrs='item') for i , items in enumerate(item): def getdivtext(classname,work): if work == 1: item_tmp = items if work == 2: item_tmp = items.find('div',class_='repost-content') tmp = item_tmp.find('div', class_=classname,recursive=False).text return tmp def imagediscovery(): srclist = [] tmp = items.find_all('img',class_="single-image") for i in tmp: a = i['src'].split('/') fix_src = '.'.join(a[4:6]) + '.jpg' srclist.append(fix_src) return srclist # 这里才是主体执行的代码,上面是方法, if i != -1: tmp_list = {} tmp_list['author_name'] = getdivtext('author-name',1) tmp_list['weibo_date'] = getdivtext('date',1) tmp_list['post_content'] = getdivtext('post',1) if items.find('div',class_="repost-content"): tmp_list['repost_content'] = {} tmp_list['repost_content']['author_name'] = getdivtext('author-name',2) tmp_list['repost_content']['weibo_date'] = getdivtext('date',2) tmp_list['repost_content']['content'] = getdivtext('post',2) tmp_list['repost_content']['image-container'] = imagediscovery() else: tmp_list['image-container'] = imagediscovery() itemdict[i] = tmp_list wbhtml.exportdata(self,itemdict) ### 存进 json 文件 我用 OrderedDict 来格式化 json 数据,存入文件完事了。 ## 结果 结果如下,虽然不能最直接展示图片,但那也是后话了,先把功能做了再说。我用 5800X 执行的话,10 秒就完事了;用笔记本的 3550H 就花了 2 分钟多。但我第一次没有优化脚本的时候,光是解析就要花 30 分钟 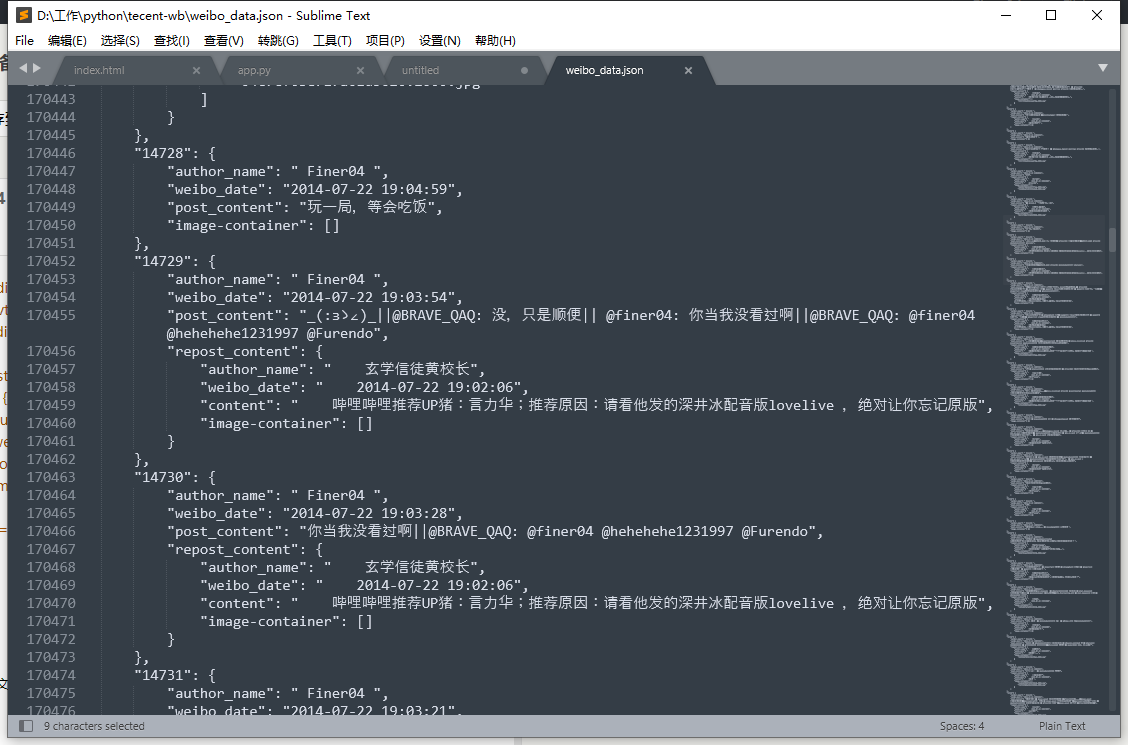 当然,我也发现了一个问题,如果有人用了颜文字,例如 >o< 这类的,就会出现解析出现问题,我目前是暂时人工删掉的。
Python
爬虫
评论已关闭
▲ Top
评论已关闭