Finer04's Blog
首页
乱写一通
脑洞破文
随便谈谈
当前播放.page
往年的故障处理分析案例
Finer04
October 20, 2023
9831 字
文章目录
在这五年我已经遇到了 300 多次网络故障,都已经是轻车熟路了。我也把以往的经历都总结到内部公司的知识库的。但我离职后也想把知识库拷贝到自己博客,不然以后那个云笔记的权限被回收了,我就没法查阅过往经历了。我就挑了近几年遇到的故障难题且不涉及内部架构的,单独挑出来说说吧。 **但是,我的总结可能未必是对的,可能有实际有出入,就当看个乐子就行了。** ## 网络故障 ### 两芯损耗问题 现象: A-B 机房是有双链路保护的,但是某天突然有频繁的闪断现象,经过供应商抢修后损耗比以前大了 3db 左右,并且某一端的端口 CRC 一直在频繁增加中。 处理方法:供应商当时很偷懒不想修复,就让我们换模块解决,因为我们是 40km 的模块,换成 80km 确实可以缓解但本质下治标不治本。一直跟他们强调这个损耗问题,让他们报上实际双路由的物理距离,计算两芯光衰差值。计算后差值比较大几乎无法使用,因此以此数据可以说服供应商尽快优化。最终供应商在某个接入间发现光缆损坏,修复后恢复正常。 首先确定整条链路的光衰,对比两芯的光衰差值是不是一样。不一样的就与供应商沟通可能是差值较大的一芯。如果两芯没问题,可以问问供应商链路的实际传输距离是多少,该距离乘上0.3的值为正常的光衰,如果实际的值大于距离乘以 0.5 则可以用这个与传输商说“这边观察到该链路的光衰是XX,正常情况下光衰是不会大于XX,麻烦查看一下"。 #### 计算 **模块损耗的临界值** - 40km 的收发光临界值:-16 dbm(收光) - 80km 的收发光临界值:-24 dbm(收光) **损耗范围** - 光缆正常损耗 0.3db/km - 可接受的损耗范围 0.6db/km *一般可以用 0.5 db/km 来计算* 尾纤有两芯,可以理解成来的方向和去的方向。 假设 A - B 端检查有无损耗,我们就要比较 a 芯 与 b 芯的光衰差值, - a 芯 = A端发光 - B端收光 - b 芯 = B端发光 - A端收光 - 差值损耗 = a 芯 - b 芯 假设 A - B 端的物理距离有 4km,利用差值进行对比 - 正常产生的损耗为 1.2 dbm - 实际可接受的损耗为 2.0 dbm - 超过 2.4 dbm 这个值就用不了,在 2.0 ~ 2.4dbm 看看有无可优化空间。 通过差值对比,可以判断究竟有无链路损耗,如果超过了损耗值就会出现异常。 ### SYN_FLOOD 攻击 背景与现象:由于公司的 DDoS 防火墙是基于 16 年的华为防火墙,研发人员逆向研究了半年防火墙,做了一台可以部署在第三方服务器的检测清洗的防火墙设备。基本流量不大的攻击都能抵御得了。但自从某一年突然来了很大的流量攻击,攻击类型是 SYN_FLOOD。由于服务器性能有限,原来 100G 的攻击流量在防火墙只识别到 400M,一直没达到 2G 的阈值。而且 400M 的 IP 在排行榜也不是第一名,让值班人员误杀了多个 IP 也无法封堵成功。 处理方法:没办法,只能找电信的人在出口确认流量,确认有 IP 达到了 100G 的流量,封堵后故障解除。 此次 SYN 攻击影响非常巨大,长达一小时的出口网络瘫痪。事后故障总结的时候,SYN 攻击直接把公司的防火墙的 CPU 直接满负荷(1000 负载),检测防火墙已经形同虚设,导致"眼睛失明"。且攻击故障异常恐怖,值班人员通过 Netflow 抓包也无法第一时间获取所有数据包信息。对最终被攻击的客户服务器其实只有 10M 的流量,服务器扛得住,但我们的互联网出口无法成功抵御到。因此这次故障只能借助上游的力量来处理。 ### 不起眼的错误包也是异常点 现象:有客户反馈一整个晚上网络质量不佳,一直存在丢包现象。接到报障后,值班人员检查了沿途传输的流量、光衰、网络质量与 CRC 均正常。最后逼得领导层,领导一查看是出口的错误包有明显上升,换了模块后就好了。 我们以前以为传输质量不佳就是传输存在 CRC,但是错误包跟 CRC 一样,出现数据错误的包也会重发的。然而当时经验不足,就没想到是因为这个原因导致异常。那时候都被领导骂的狗血淋头了。有些交换机没法拿 CRC 用来监控数据,因此在我们的 Cacti 中只能拿错误包当 CRC 监控。 该图实际上丢失包,但丢失包不影响网络质量,我没找到配图,你们就假装这条黄色线就是错误包吧。正常来说错误包应该为 0 才可以,如果有过突升或持续上升,说明传输质量有问题,必定是哪一端有损耗。 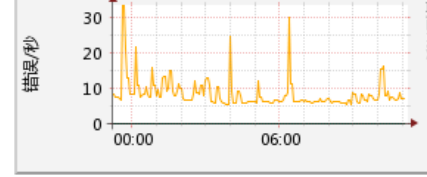 此外,我也遇到接入层到汇聚层的链路异常问题,也是错误包。往往看到 A 端有错误包的话,我们就考虑更换 B 端的光模块或者换条尾纤是否正常解决异常。如果不行,也有可能是板卡的问题。 ### 出口故障的依据 使用互联网出口,有时候拨测全国的 IP 都有问题,最开始的话肯定是用 `mtr` 进行故障定位,但 `mtr` 的资料在另一台电脑还没找出来我就不详情说了。简单来说,通过 `mtr` 测试对端 IP,看哪一跳开始出现 **连续丢包** (就是从这一跳开始到最后一挑的 IP 都大于 0% loss)或者往下不可达的话,这里就是问题点了。 看一个路由追踪图,我们要拆开数据来看 - 本地互联(本地路由) - 172.16.0.5 (NAT 网关或者其他设备) - 192.168.1.5(核心层地址,就当他是吧) - 互联网出口互联(外网网关) - 172.88.1.1(运营商与我们设备的互联 IP) - 骨干传输(沿途传输) - 5.5.5.5 - 8.7.8.4 (随便输的) - 对端内网互联(对端的网络环境) - 183.5.4.2 (对端网络的互联) - 183.5.4.80 (对端网络的网关) - 目标 IP - 183.6.5.10 (对端 IP) 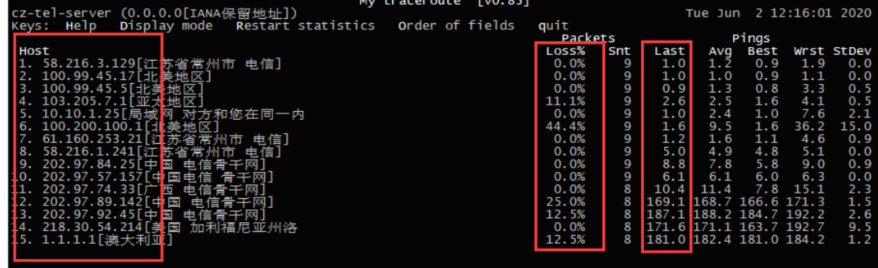 一般来说,出了本端互联后丢包的话,都属于外网的问题,包括骨干网与对端网络问题。因此通常如果有资源的话,我们也会在对端IP 测本地 IP 的路由追踪图,根据两份追踪图可以更准确了解具体问题点在哪。我大多数见到的运营商故障就分为 普通故障、省内故障、全国故障 这三大类。 当然,有些客户比较离谱,用移动的IP报障到电信有丢包,其实也能跟上游报障,但没法保证能修好,也有可能是电信的问题,也有可能是移动的问题。我们一般忽悠客户跨网无法保证稳定的网络环境,或者直接甩锅说是电信或联通的问题,嘿嘿。或者说,有些客户说你这个路由图怎么走到美国了,明明两端都是国内的IP。我只能说不要太相信 IP 归属地,有些互联 IP 不一定是公网 IP,而且 IP 可以任意 anycast 广播到其他 BGP 节点,所以只能当参考。 如果出口互联有问题的话,假设我们的出口是冗余的,不同的出口端口都有独立的互联地址,我们也要看清楚是哪个端口有问题,也许那个端口的流量已经掉光光了,但路由依旧走有异常的出口。 #### 还有,不要太迷信路由追踪图的 loss 值 有些客户就说,怎么这个骨干一直丢包呢?但看图下面都没连续丢包,`因为 ICMP 本身就是优先级比较低的队列,设备会优先处理其他高优先级流量,再处理 ICMP,所以这种 jitter 并不能说明故障`。这套说辞换通俗点来说,就是骨干设备为了性能会舍弃一些低优先级的数据包如 ICMP,因此不是真正的丢包。 ### 有些 IP 突然无法访问外网 这种情况也有客户报障过,说自己的 IP 平日都用得好好的,下午突然没法用了,当时我们经验不足,网管又说检查不了问题,最后通过数据检查确实是网管做数据有问题。如果遇到这种问题,我一般这样确认: 1. 确认客户防火墙是否限制了(让客户做mtr,我们自己看) 2. 检查交换机的 QoS 策略中,ACL 是否正确放行了 IP(有些策略是通过 IP 进行限速的,有时候网管同事写错反码或漏IP) 3. 确认运营商路由是否正常(有可能回收路由做错了,如果交换机网关能ping通客户IP,外网不可以的话基本是这样) 4. 接笔记本或换 IP,确认究竟是否是设备系统异常。 5. 检查交换机是否做过 ARP 绑定,或者有可能 ARP 欺骗。(前者的话一般是割接没解绑导致,或者用户的安全狗做ARP保护了;后者的话就是中间人攻击,可以用交换机强制绑定) 基本遇到都是这样,排除自己的问题才好报障到上游,当然我也遇到过上游不给我们处理的事情,可能是钱没给到位。 ### 一个环路导致整个网络的瘫痪 以前有过一例非常严重的故障,就是因为一个传输出现环路,导致从某市机房到其他机房的网络完全瘫痪。虽然不是我值班,但是一定要定位好故障问题点。 事件全貌我找不回来了,这个我要翻翻以前的记录才行。但是作为监控的话,故障来了会有很多告警,我们一定要抓住主要与次要的点。我们要关注的告警,如果是我的话我就会这样看 1. 查看日志,看故障来临的首个时间点来看。 2. 查看可能是问题点的告警,优先级:物理端口、环路、路由、虚拟链路。 - 以前做了公网隧道,如果物理传输有问题的话,公网隧道也会有一堆告警,但虚拟链路是衍生告警,不是最主要的。 - 环路会有环路保护(如果配置了),会自动关闭有异常的链路,除非没配置。但都是关键点,有环路导致数据包一直在循环乱成一锅粥。 - 路由告警肯定会有一堆,但是可能物理因素导致的,跟第一条的隧道一样可能是衍生问题。 3. 看网络情况,全部节点有问题的话,那肯定是内部有问题,不可能所有出口有问题,除非大灾难来了。 当时值班人员整麻了,我介入了后才好分析问题,但无论情况多糟糕,要找到问题点,才好方便升级问题,不要当无头苍蝇,会耽误很多没必要的时间。 ### 排障不仅抓宏观,还要抓微观 #### 注意核心层-汇聚层-接入层的流量 有时候看问题太过宏观了,反而没从微观角度寻找问题。 之前有客户丢包,我们太关注大网和出口流量,或者直接看客户的接入端口流量都很正常。值班人员一直查不出问题就跟客户说没事,但实际上我一查接入层到汇聚层的流量都跑满了,肯定会塞。相当于小出口的流量都瓶颈了。 #### 交换机也是有性能瓶颈的 不要以为交换机的几十 Tbps 就很无敌,也要关注 CPU 占用。 之前某个机房的有很多客户报障有丢包,我们也像上面一样,流量都关注没问题,mtr 看确实在内部有问题,但内部端口都正常,一直查不出问题。网管排障后发现,因为有客户流量比平时跑得高,但就只跑了 6G 而已,还没到端口 10G 的上限哦。然后偷偷给客户限速,发现丢包问题缓解了! 后面网管关闭了交换机的镜像流量,初步判定可能是板卡的端口只能处理 5G 的流量;也有可能镜像流量太大了,还是多个观察组,CPU 有点扛不住了。后面割接,换上更换的交换机,镜像流量使用物理分光器,不使用交换机的镜像功能。 #### 检查路由表哦 这里的路由表就是交换机的路由表,我一般在核心层或者出口层 `dis ip routing-table x.x.x.x` 查看下一跳地址是什么,检查是不是指空了,或者路由指到了不存在的设备。这些问题都是有过的,很多事情都是以前人为问题没有清理干净数据,交付的时候才发现有问题。 #### 直通的安全设备也是隐患点之一 为了安全,有些客户是部署了安全设备,例如安恒或者深信服这些。这些安全设备都需要做直通,就是所有流量一定要经过安全设备才可以。有些客户购买了我们的安全产品一年,所有流量都要经过虚拟防火墙,保证他们的安全。 但有一晚深夜,还好是我值班,其他同事值班完全不知道什么事。有个买了我们下一代防火墙的客户突然报障,问我们出口是否正常,今晚突然服务挂了一阵子。但我检查出口和传输都没问题。客户突然又说又挂了赶紧确认,我再检查下一点告警都没有。惹得客户都不开心(还好我是见过客户本人,比较好沟通)。 我想是不是安全资源池问题呢?因为客户他也认为可能是安全资源池的问题,刚好又故障复发了,这下子可以当场抓老鼠了。一登录我什么都不用看了,看到 CPU 和内存的图表都占满了,再通过客户今天的报障期间查了下历史图标。正好有异常的时候,图表的 CPU 和 内存都是高占用的。已经确认是安全资源池的问题。 深夜也没工程师鸟人,客户也扛不住先睡了。下一天客户让我们先取消引流并让我们上报给工程师。工程师看了下以为可能是客户有恶意流量,给他设置好安全策略好。第三天又复发了,刚好又是我值班,我也配合客户确认,CPU 又上升了。还好是白天班,工程师也一起确认了问题。工程师把 AF 进程导出给技术做黑盒测试。发现进程确实有内存溢出的 Bug 问题。修好了后客户就再也没问题了。  所以路由追踪图的任何一个细节都不要放过。勿以善小而不为。 ## 设备问题 ### 交换机电源更换 现象:交换机出现掉电情况,但还好是双电源模块只坏了一个,但在实操中不知道如何更换。 双电源备份的其中一个电源掉电,如果电源是连接市电的话,理论可以不会受到影响,不过如果市电也断电的话,会单电源(UPS)能支撑的时间会少很多,或者直到单电源支撑不了了(电源模块2也坏了、哪一天机房又停电了UPS撑不住、UPS供电异常等等),后果将会不堪设想。当另一个电源也掉电,那交换机没有供电而停止工作,从而影响使用该交换机的客户。 如何更换呢?我们从命令行与实际情况确认究竟是哪个电源有问题。但一开始,先确认交换机信号,就像下面这台是 S6800,更换电源就要找兼容 S6800 的电源模块。命令输入 `dis version` 确认设备信息。 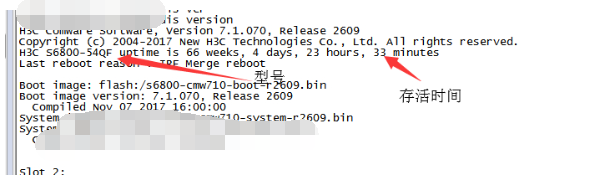 实际去到设备面前,我们要看右侧的 `PWR` 有没有橙色灯。因为有些设备是做了热备或者 IRF,我们未必去对正确的设备,所以物理层的确认也是很重要的。如图所示,`PWR2` 灯就橙灯了,我们就要找到 PWR2 机子背面是哪一块。  有些 6800 背面已经表明哪个模块是 PWR1/PWR2,但其他交换机可能未必会标记,会有一个箭头指着哪个是 1 哪个是 2。本来想配个图的,但我没存下来,网上文档也没标记,因此要从实际设备为主,肯定是有个标识的。 ### 光纤模块 公司为了降本,一般能用库存的模块就用,没有的话就先拆掉空闲服务器的模块,拆东补西。导致有时候我借公司的服务器没有模块用,申请模块的时候又很无知,不知道单模和多模的区别。借了插进去识别不了,一直 UP 不起来,原来不同的模块也有兼容性问题。 服务器一般用多模的服务器模块(主要型号:Intel);接线的话,交换机端接交换机模块,而服务器接服务器模块,不能混搭。同时除了模块,也要注意服务器有没有装网卡驱动,应用是否支持该厂商的板卡这些问题。以前我辛辛苦苦借到了一张博通的万兆网卡,结果部署应用一直起不来,后面厂家说只适配了英特尔的... **多模和单模的区别** - 单模适合长距离传输,传输速率要求高(长途传输等,适合长距离) - 多模适合传输速率低,传输距离较短的网络(服务器都是用多模,因为短) ### 阵列或者一些厂商的存储 怎么做阵列我就不展开了。我就说下我遇到过关于硬盘的破事。 #### 预算充足的话建议不要上 Raid5 曾经有几台安全设备,以前的同事都给他们做 RAID5,RAID 5 的空间利用率比较经济,虽然坏一个盘还是能撑得住。但是实际上,我遇上几次掉一个盘,第二个盘也准备掉的问题(5盘组RAID5)。当初我们巡检可能不及时,或者真出现坏盘了,我们没法第一时间知道(R410 没有 IDRAC 或业务不重要),就一个坏盘冒红灯了,我们过了很久才知道坏了。 知道了后就赶紧换一块,REBUILD 完了以为可以收工了,没想到第二块盘也掉了,强制上线也不行。同事建议直接重做算了,反正数据也不重要,可以远程同步回去。最后直接重做阵列,全部硬盘换了,做个 RAID 1 放心点。 我还以为是个例,网上也有讨论 《[关于为什么RAID5往往掉一个盘后第二个盘也立刻挂掉的原因分析](https://www.bilibili.com/read/cv2384532/)》。大概就是说只要有一个扇区有问题,剩下的硬盘没法提供足够的 CRC 数据了,数据没法正常读取成功了。这篇文章分析很到位,因此建议能不RAID5就先不 RAID5。 #### 内存插槽 服务器的内存插槽不能随便插,拆下盖板,盖板背面就有一个内存说明图,按照顺序装内存才能成功识别。有些机房同事是新人什么都不知道,直接全部插上去,开机就 BIOS 报错了。 有时候想扩容内存,但不知道目前服务器装了什么内存条,频率多少都不知道。用 `dmidecode -t memory` 可以确认。 还有一个内存故障,可以查阅我之前写的文章:[硬盘不行就不要依赖 swap 了](https://lowb.ren/archives/dont-rely-on-linux-swap.html) 确实不能用 swap,别人 K8s 安装都要求不要开启 swap 了。 #### 不要省事(深信服 CSSP) 之前部署了一套深信服安全资源池,但是是第三方服务器,深信服只能提供软件上的支持。那时候在机房申请了几块 500G 硬盘凑个 2T 空间就先交差了。但部署完后,暂时没客户要用到安全资源池,就放置了大半年没管。去年九月的时候,有客户先申请使用,我本想着用旧的 CSSP 来交付,但领导说旧的要给钱,新的你不用?那我就索性在新的 CSSP 开租户给客户。 客户要求要 AF 和 日志审计,开完 AF 想开日志审计,但一直出错但又不告诉具体原因。问了厂商才知道,日志审计要预留 1T 的空间,但在服务器的硬盘虽然有 10 块硬盘,但要为了冗余与备份,实际只能用 1.5T 左右,系统又要吃一定空间,开不了哦! 深信服安全资源池都是单硬盘直通的,就是不需要做阵列,第三方服务器的话,所有硬盘都要单盘 Raid0 或者做 JDOB。当时我还以为要做阵列。比较麻烦的是,换硬盘都要重新做 RAID0,机房人员还比较水,还得接 KVM 让我远程操作。我也很水!我也是让同事一起看才放心做。 本以为再插几块硬盘就可以解决,但是!没硬盘槽了!!而且这大半年,系统已经坏了两块硬盘了!我用聊天记录的形式来回忆当时的情况吧。 ##### 事情经过 > 我:李工啊,我们这 CSSP 还有救吗,能加硬盘来缓解吗? > 李工:HCI 的硬盘扩容要保证全部硬盘正常才可以扩容哦! > 我:那我先把坏的硬盘拆下来重建吧。 > 李工:你换好就直接点击 "硬盘修复" 来自助恢复数据吧。 我让机房更换好硬盘,其中有一块硬盘是 1T 的,直接在 HCI 重建硬盘,但是重建到一半报错了,也不知道原因。 > 我:李工啊,好像又出幺蛾子了,怎么报错了 > 李工:我让技术看看吧。可能要在后台强制上线哦,你新换上的硬盘没法恢复坏掉硬盘的数据哦。 > 我:没问题,反正业务还没上线,只开了一个模块。 李工让技术在后台重新上线,都重新恢复上线了。但有个问题还没解决,还是不够空间啊! > 我:李工啊,我更换了一块硬盘是 1T 的,正常来说能多出 500G 够开模块吧,怎么 HCI 的总空间还是 1.5T 呢? > 李工:啊,如果你之前的硬盘是 500G,那你的 1T 硬盘重新上线后只能当 500G 用,因为元数据是当这块 1T 硬盘是 500G 的哦。 > 我:我超,辛苦半天瞎折腾! 那段时间客户一直催着问日志模块开好没,要开始等保了啦!我都有点想逃避了,不知道怎么回客户。想了想...客户的业务也没正式用,那就亡羊补牢吧,直接重新部署 CSSP 吧!骗客户说要升级安全资源池版本,实际上也是升了,一举两得。 > 我:李工啊,要不要加个班,我想定个时间重新部署安全资源池,顺便升个级吧,从根本上解决问题,不然客户多了也撑不下。 > 李工:对啊,太折腾了,重新做呗,我去申请个加班费先。  这次我直接借了几块 1T 硬盘,总空间到 5-6T,这下用到公司倒闭也可以,从根本上解决了问题。取消引流,找到 USB-KEY,重新配网,重新导入模块的数据,搞定了~ 所以搞项目一定要想得长远一点,我这次确实太省事没有考虑到这些问题。 ## 沟通的艺术 沟通这块一直是我的软肋,有时候电话沟通的时候太紧张,或者太直白,或者听得大家一头雾水。所以我才玩 VRChat 来训练自己的沟通,也在做了一年的服务台才知道怎么更好的沟通。 1. 开头一定要先自我介绍,不要先问对方是谁谁谁 - 人家以为你是诈骗电话会挂。最好先说我们是哪家公司,让客户马上想起是跟他有关的。(因为固话没有归属地) 2. 客户很急也不要跟他一起急,故障已经发生了就要有条有理来处理 - 故障已经发生了,我们不是神仙,没法下一秒立刻能处理完。所以要好好安慰客户,把手里知道的情况跟客户说说,骗一下也行,至少让他看到点眉头。如果自己也急了,很难静下心去处理问题。 3. 说话不能说太直 - 这是我一直的老毛病,最近面试也是一样,不会圆滑,我家人也在说我这个诟病。其实我也意识到,就是因为自己急了想到什么就说什么,不经过加工就说出来。 4. 沟通一定要有思路,方便自己全面了解事件全貌 - 一定要避免这种情况,想到什么就问客户,显得自己很没条理,客户也嫌烦。 - 帮客户处理故障一样,首先问清楚,什么现象、时间点、路由追踪图、持续时间、源IP目的IP,有没有做过什么特殊操作等等,先把这些基础问题甩给客户,方便我们上报问题。可能有些问题就是客户自己的问题,我们啥都不知道直接上报到供应商,供应商就觉得我们很 low-level . 5. 大家都是人 - 不要因为对方的身份多高就畏惧,很多事情能正常沟通的,自己不要害怕。 6. 立场要坚定点 - 不要太优柔寡断,明明是对方的问题,自己却被客户的无理解释说服了。到头来还是客户或者供应商有问题,会让自己很憋屈。 ## 最后 有一些小故障我就不单独拿出来讲,我都忘了,或者不值得说。 多多总结与反思,做自己的知识库,这样温故而知新,更好的了解过去,应对未知的未来。
1 条评论
victor
October 30th, 2023 at 02:38 pm
谢谢!学习到了
评论已关闭
▲ Top
谢谢!学习到了